On September 14th, 2023, the Methods Lab organized a workshop on the rationale and methodology of theory building in empirical research. The workshop was conducted by Adrian Meier (U of Erlangen-Nürnberg) and aimed to provide participants with an orientation for working with theories in a meaningful way that provides a foundation for empirical research.
In the first section of the workshop, Adrian outlined what theories are and how they relate to the overarching mission of science. The introduction focused on the differentiation between theories, concepts, constructs, and models and addressed the interplay between theories and empirical research.

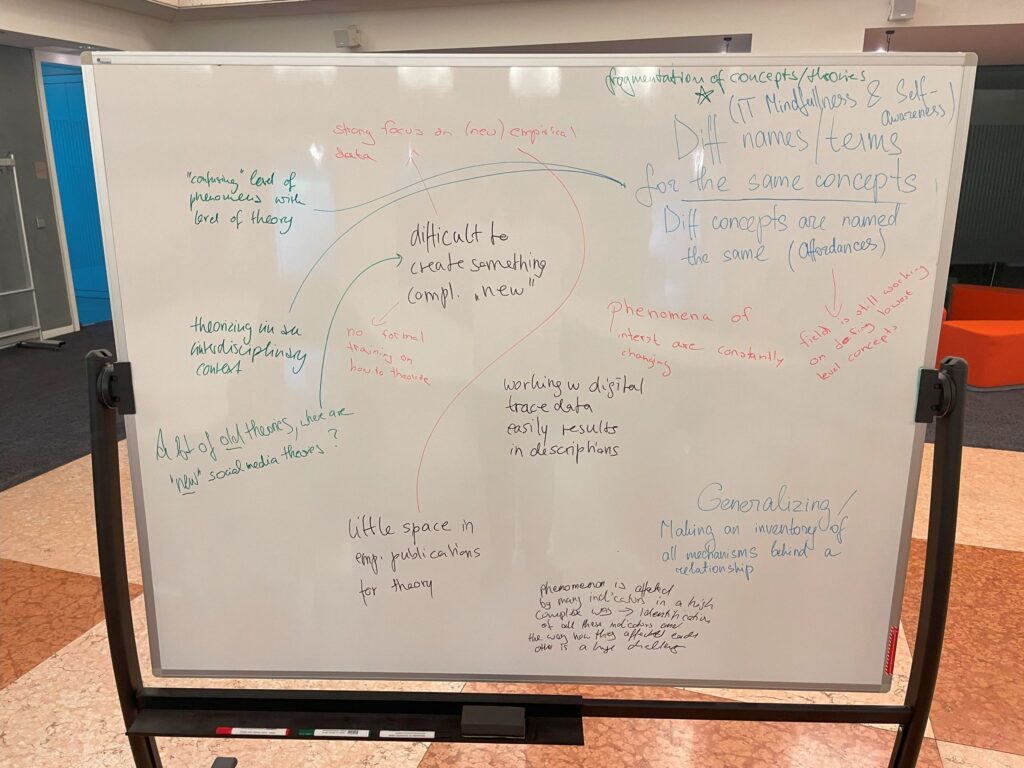
After this introduction, the focus shifted to challenges and problems of social scientific theorizing. Participants were given the opportunity to add issues and questions they identified in the past when working with theories. Most prominently, they mentioned confusion due to different terminology that is used for specific concepts (i.e., synonymy and ambiguity), the “moving target” problem (as phenomena are changing while they are being studied), and the lack of incentivization to focus on theory in the formalized infrastructure of empirical research. Adrian elaborated on some of the underlying issues uniting many of these challenges: Theories are underdetermined by evidence, concepts and measurement instruments are rarely validated, and manipulations in experimental research are not precise enough.
In the last section of the workshop, participants learned about a recently proposed Theory Construction Methodology (Borsboom et al., 2021) and took part in an accompanying exercise. They were asked to read a one-pager summarizing crucial elements of the Mood Management Theory, a popular theory in the field of media psychology. Within this text, they should identify statements about phenomena the theory is supposed to explain, data that supported it (or not), as well as the theoretical statements (e.g., premises, propositions) themselves, to increase participants‘ sensitivity in differentiating between these elements in their own work. Lastly, Adrian gave an outlook on how theories can be formalized and how theory construction can be crucially fostered by non-confirmatory research practices.
The workshop was a great and unconventional addition to this year’s series of workshops organized by the Methods Lab. Adrian structured and executed it brilliantly and gave participants – who were associated with various fields of research and very engaged – lots of room for discussions.
We would like to thank Adrian for his thorough and inspiring workshop and hope he will contribute to the Methods Lab program again in the future. In the meantime, we recommend following him on X for updates on his research!