Interested in learning new research methods, building your programming skills, or exploring how AI can support your research? Instats is a global learning platform providing live and recorded training seminars in statistics, programming, research methods, and AI. Most seminars require a fee, but several sessions are also freely available after registration.
For example, many researchers have already benefitted from Peter Gruber’s presentations, such as AI Tools for Researchers 2.0. This fast-paced overview of AI tools supports every stage of the research process, from literature reviews and data analysis to academic writing. It also demonstrates how to make effective use of popular chatbots, specialized AI tools, and open-source models, showing what is convenient and what is worth paying for.
Those looking to explore more advanced applications may be interested in the workshops offered by Piers Steel and Hadi Fariborzi. Beyond ChatGPT: Agentic AI as 24/7 Research Assistants focuses on using agentic AI to automate research tasks such as data collection, analysis, and reporting for both qualitative and quantitative AI-driven methods, while Beyond ChatGPT: Using AI to Enhance Research Workflows covers ethical considerations when integrating AI tools into everyday research activities to improve the quality and efficiency of your work.
The platform also provides opportunities to network with hundreds of peers across institutions and disciplines, discover open research positions, and access additional professional development resources. Take a look!
Over 4,000 communication scholars from around the world gathered in Cape Town, South Africa, from 4-8 June 2026 for the 76th Annual Conference of the International Communication Association (ICA). This years theme, “Communication and Inequalities in Context,” invited researchers to examine how communication structures reflect, reproduce, and respond to social inequalities, such as unequal access to information, digital divides and power dynamics that influence knowledge production in communication research.
View on Devil’s Peak and Table Mountain
The Weizenbaum Institute was represented by several researchers who presented their work. A special congratulations goes to Roland Toth from the Methods Lab, who received the Mobile Communication Top Paper Award. His award-winning paper, co-authored with Douglas A. Parry (a Methods Lab research fellow) and Julius Kingelhoefer, examines reactivity effects resulting from providing access to Android event logs and participating in Mobile Experience Sampling studies, contributing to a better understanding of how research methods can influence participants’ smartphone use.
Presentation of the ICA Mobile Communication Division Top Paper Award
The award recognizes the international impact of Weizenbaum research and marks another successful ICA 2026 for the institute, where researchers also had the opportunity to encounter some of South Africa’s cutest wildlife (see the penguins pictured below).
We are pleased to announce the launch of a new local instance of OpenQDA, now accessible at https://openqda.intern.weizenbaum-institut.de/. This instance is hosted within the Weizenbaum Institute and provides researchers with a dedicated, secure environment for qualitative data analysis. As of now, LDAP authentication is not yet implemented, so access requires being on the Weizenbaum Institute network or connected via VPN. To create a new account, please access the link at the bottom of the landing page.
OpenQDA, developed by ZeMKI at the University of Bremen, is a free, open-source, web-based alternative to the commercial software MAXQDA. It supports core coding functions, follows the REFI standard for project interoperability, and enables collaborative workflows with versioning and shared codebooks. The platform also offers basic visualizations and is designed with GDPR-compliant data handling in mind.
This local instance builds on our earlier announcement of OpenQDA and reflects our commitment to open, collaborative, and ethically responsible research practices. The full source code is available on GitHub under the GNU Affero General Public License v3.0, and the ZeMKI welcomes feedback and contributions from the research community.
We encourage all researchers to explore the platform and help shape its development!
The crisis in academic publishing, along with its various sub-crises (the replication crisis, the procurement crisis, the AI-driven transformation of research, etc.), remains a topic of widespread debate. However, high article processing charges (APCs), oligopolistic publishing structures, and the dominance of reputation-based journals continue to shape scholarly publishing.
Fortunately, there has recently been a growing number of initiatives that go beyond merely diagnosing the problem and develop concrete solutions in the form of new infrastructure offerings. The ideal that many within the scientific community could agree on would be a resilient and decentralized publication infrastructure designed by scientists for scientists, one that takes into account the heterogeneity of the scientific landscape and disciplinary cultures while also providing financial relief. While the Chinese Academy of Sciences is taking initial action and deliberately ceasing to pay publication fees for certain international OA journals using academic funds and grants from the central government (thanks to Anne Krüger for this reference), a promising alternative is now emerging in Europe:
The open-access publishing platform Open Research Europe (ORE), which until now has been available only to beneficiaries of EU research framework programs, will be available free of charge starting this fall to all researchers working at German research institutions, regardless of whether they receive project funding. This is made possible by a consortium of research and funding organizations from eleven European countries, which will support the publishing platform starting this year. The contractual partner on the German side is the BMFTR, while the DFG is responsible for implementing the project at the national level.
For WI researchers, this will likely result in two concrete opportunities starting in the fall of 2026:
Open-Access Publishing Free of Charge for All Disciplines ORE offers a free of charge alternative to the often prohibitive APCs charged by commercial publishers. Since the platform covers all academic disciplines, researchers in the social sciences, natural sciences, humanities, and beyond can publish their findings without financial barriers. This is particularly relevant given that the open-access transformation is still stalling in many areas. While some disciplines already rely heavily on preprint servers or Diamond OA journals, other fields still lack sustainable, non-commercial publication channels. ORE could fill this gap without the usual reputation mechanisms often tied to expensive journals. As the DFG emphasizes, with ORE, “academic prestige is not generated by the journal’s name, but by the scientific content of the individual publications and the assurance of high-quality processes at infrastructure level” (DFG, ifr-26-21). For researchers who wish to break free from the logic of impact factors, this likely offers an attractive opportunity to make high-quality research visible.
Active Participation: Peer Review and Community Building ORE is not only a publishing platform but also a community-driven project. Researchers can get involved as reviewers: an opportunity to help shape the platform’s academic quality while showcasing their own expertise. Although, as with most publishers, peer review is most likely unpaid, the activity can be listed on an academic CV as a commitment to open science. Additionally, it offers networking opportunities with colleagues from various countries and disciplines. Those who get involved early on can, in the best-case scenario, actively help shape the development of a vital infrastructure for the future of scholarly publishing.
ORE could be an important step toward reforming the publishing system. It is therefore worth keeping an eye on its development and even getting involved early on.
Data visualization books now available at the Weizenbaum Institute library
You may remember last year’s Methods lab survey assessing the institute’s methodological training needs, which found that 20% of participants requested additional support in data visualization and modeling. After the success of the scientific data visualization workshop led by Dr. Ansgar Hudde in winter 2025, the Methods Lab would like to provide ongoing support until the next workshop, with a curated collection of comprehensive data visualization books. The following books are now available in person at the WI on-site library! Read further to find more books, freely accessible online.
Data Visualisation: A Handbook for Data Driven Design (3rd Edition) by data visualization expert, Andy Kirk
This book includes more than 200 examples showcasing data visualization in a broad range of fields. At the same time it combines critical, conceptual, theoretical, and practical thinking to help developing deeper insights.
Better Data Visualizations: A Guide for Scholars, Researchers, and Wonks by data visualization expert and economist, Jonathan Schwabish
This book includes over 500 data visualization examples and teaches how to design clear, engaging visualizations via practical techniques, visual principles, and a large array of chart types to better communicate information.
Critical Visualization: Rethinking the Representation of Data by researchers, Peter A. Hall and Patricio Dávila
This book discusses how data visualization is never neutral, tracing its historical, cultural, and political roles while including critical, inclusive, and participatory ways of representing information.
Visualize This: The FlowingData Guide to Design, Visualization and Statistics (2nd Edition) by statistician, Nathan Yau
This full-color book offers a step-by-step guideto visualizing and storytelling with data, combining tool and programming examples, statistical analysis, and design to create clear and meaningful graphics.
Data Sketches: A journey of imagination, exploration, and beautiful data visualizations by data scientist, Nadieh Bremer, and data visualization designer, Shirley Wu
Accessible to those at every level of expertise, Data Sketches documents the creative and technical process behind 24 innovative data visualizations, giving thorough examples for data collection, coding strategies, and methods of artistic storytelling.
On top of that, we have identified multiple books on data visualization that are freely accessible online. Please check them out, following the link in each title.
This book reveals the artistic thought processes behind numerous leading designers and teaches how to transform raw data into well-defined, engaging graphics through analytical thinking, visual design, and storytelling.
This book shows how to turn data into clear, compelling visual stories by teaching effective graph selection, design principles, audience-focused communication, and storytelling techniques.
This book demonstrates how visualization turns complex data, such as subway maps, brain diagrams, and personal habits into insightful graphics, revealing meaning through design, color, and storytelling techniquesused by two dozen expert practitioners.
This book provides a thorough and practical approach for creating science-focused explanatory diagrams, integrating evidence-based design strategies with worksheets to guide projects from concept to finished visualizations.
This text teaches readers, regardless of coding experience, how to build interactive, web-based data visualizations using D3, HTML, CSS, and JavaScript, with step-by-step examples, animations, maps, and real-world case studies.
With over 250 illustrations of statistical graphics, this book gives detailed guidance on presenting complex information through maps, charts, tables, multivariate designs, small multiples, and high-resolution displays, emphasizing clarity, precision, effective analysis, and the avoidance of graphical deception.
This comprehensive guide shows how to design precise, informative charts and tables, with updated content on quantitative narrative, misuse of donut, circle, unit, and funnel charts, plus instructions for table lens displays, box plots in Excel, and effective color palettes.
This book serves as a companion to Show Me the Numbers, teaching readers to analyze quantitative data through example-based “thinking with our eyes,”using techniques applicable to several data analysis tools, revealing patterns, trends, relationships, and exceptions.
Researchers from Freie Universität Berlin and Weizenbaum Institute gathered on May 12-13, 2026, for a workshop on digital ethnography jointly organized with the DiMES and Methods Lab.
Daniela Jamarillo-Dent introduces the scroll-back method
The workshop introduced the theoretical foundations of digital ethnography and explored a range of methodological approaches, including walkthrough, walk-along, and scroll-back techniques, alongside hands-on exercises focused on the platforms TikTok and Instagram. The workshop was led by Dr. Daniela Jaramillo-Dent (University of Zurichand Università della Svizzera italiana).
Daniela Jamarillo-Dent introduces different techniques in digital ethnography
Participants learned about conducting digital ethnographic research on social media platforms and explored how platform affordances and vernaculars shape online behavior, engagement, and forms of connection, with particular attention to marginalized communities and hard-to-reach groups. Through guided walkthrough exercises examining digital platforms, researchers reflected on field note-taking, multimodal analysis, reporting practices, and different approaches to sampling social media content. The subsequent scroll-back exercise focused on user-centered research approaches, incorporating users into the study process, and interviewing research participants.
Participants engaged in workshop exercises
Discussions emphasized the importance of researcher positionality and reflexivity in digital ethnographic research, as well as researcher well-being, informed consent, and the well-being of research participants. Overall, the workshop provided practical methodological tools and critical perspectives for conducting ethically grounded digital ethnographic research on platforms.
On April 28, 2026, researchers from the WI gathered for an engaging workshop introducing Open Paper – a next-generation content management system designed to break free from the constraints of traditional publishing formats. The session centered on a core idea: knowledge shouldn’t be confined to linear, static documents. Instead, Open Paper enables dynamic, interactive publications that adapt to how readers actually engage with content. By replacing rigid PDFs and blog posts with modular, navigable experiences, the platform empowers authors to create richer, more intuitive reading experiences. The workshop was organized by Merja Mahrt and Esther Görnemann from WI together with the Methods Lab, and Markus Brandenburg and Fabian Hassel from the agency that has developed Open Paper – MADEFUL – were invited as speakers.
In the workshop, participants explored how Open Paper transforms static text into living publications. Through a hands-on demo, they discovered features like:
Flexible layouts with multi-column arrangements and responsive design
Interactive expositions that allow readers to dive deeper into subtopics while maintaining context
Self-contained chapters that make content accessible even when read out of order
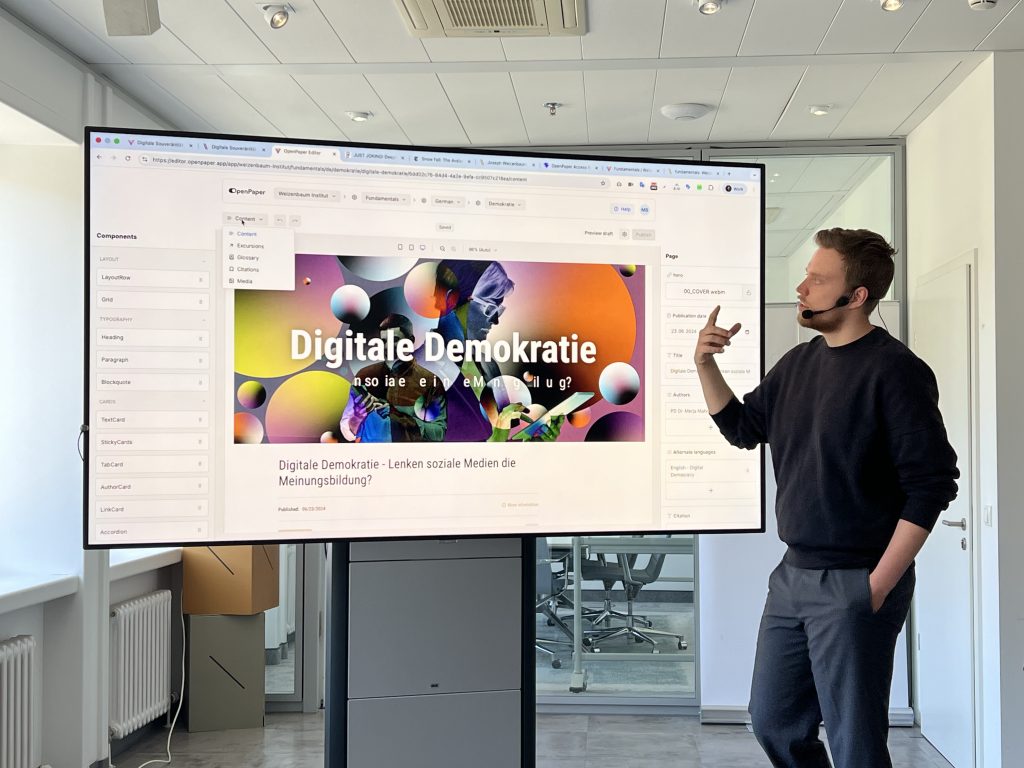
Esther Görnemann provides details on the production of the fundamental on digital sovereignty
The real impact was seen in an overview over digital sovereignty as part of the Weizenbaum fundamental series – a flagship example of what’s possible. With interactive visuals, side-by-side comparisons, and layered explanations, the publication achieved an average reader engagement of 26 minutes, which is a clear indicator of depth and interest. Even more telling: traffic increasingly comes from AI tools like ChatGPT, signaling that the content is not only readable but reusable and referable in emerging digital workflows.
Beyond design, Open Paper was built on strong ethical and technical foundations: open source, open access, GDPR-compliant, CO₂-neutral hosting, SEO-friendly, and fully accessible. Like the Weizenbaum Institute, other institutions can also deploy a custom instance aligned with their corporate design, ensuring brand consistency and long-term ownership.
Markus Brandenburg explains how to add and edit different types of content in Open Paper
The workshop’s interactive phase let participants discover how to build a page in real time using a three-panel interface:
Left: Structure and layout tools (grid, headings, visual elements)
Center: Live preview of content and layout
Right: Contextual editing options for the selected element
Beyond the workshop itself, the presenters further created a tutorial video made available on the WI’s Open Paper instance.
Rather than offering a one-size-fits-all template, Open Paper encourages authors to think critically about audience, structure, and engagement. It represents a shift in how we think about knowledge sharing: interactive, inclusive, and built for the future.
The fourth edition of our Introduction to Programming and Data Analysis with R workshop took place on March 25 and 26, 2026 continuing the tradition of hands-on, beginner-friendly training in R—a powerful tool for data science and statistical analysis. For those who attended previous editions, the structure and content remained familiar and effective: a two-day immersive experience covering the fundamentals of R syntax, Markdown/Quarto, data wrangling, analysis, visualization, and reproducible research practices. If you are new to R, or looking to refresh your skills, this workshop remains a great starting point.
Roland Toth provides an overview of the workshop goals
We’re proud to see a consistent number of participants attending each year. The workshop’s format has been shaped by feedback from past attendees, and we have kept the core curriculum intact to ensure a smooth learning curve. If you missed this year’s session, you can still explore the material through our previous recaps:
These posts offer summaries and key takeaways—perfect for catching up or preparing for the next edition. Stay tuned for updates on the 2027 workshop, and keep coding with R! 📊💻
Join us for the workshop Walking Through and Scrolling Back: Digital Ethnographic Methods for Platform Research, organized by the Methods Lab. On May 12–13, 2026, Dr. Daniela Jaramillo-Dent will introduce participants to innovative ethnographic approaches for studying visual and interactive social media platforms.
This hands-on workshop focuses on two complementary methods: the walkthrough method and the scroll back method. Participants will learn how to engage directly with platform interfaces to better understand how design features, technological mechanisms, and cultural references shape user experiences. In addition, the scroll back method will be explored as an interview-based adaptation, inviting participants to revisit their own platform histories and reflect on their interactions and meaning-making processes. Through practical exercises and examples from digital communities, the workshop offers valuable insights into how discourses emerge and evolve on visual platforms such as Instagram and TikTok.
The workshop is designed for beginner to intermediate researchers who are interested in expanding their qualitative methodological toolkit.
Seats are limited. To learn more, please visit our program page. We look forward to welcoming you!
Great interest in the 12 high-density presentations
On March 19, 2026, the “Data, Archive & Tool Demos” panel returned at the annual conference of the German Communication Association (DGPuK) in Dortmund. Co-hosted by the Methods Lab lead Christian Strippel, colleagues and the GESIS Methods Hub, the panel brought together researchers to present and exchange reusable research data sets, archives, collections, and research software that promote transparency, collaboration, and methodological innovation in communication and media studies.
A total of 12 projects were presented, including the Platform Governance Archive, OpenQDA, the GESIS Pretest Database, the German Scandal Database, FID Media Publish, and a community data trustee for researching the far right online. The projects were first introduced in short presentations. Afterwards, interested colleagues from the audience could learn more about each project at poster and demo stations. As was the case two years prior, interest in the format was very high. This motivates us to continue offering this format in the future.
Manage Cookie Consent
To provide the best experiences, we use cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.