AI systems rely heavily on workers who face precarious conditions. Data work, clickwork, and crowdwork—essential for validating algorithms and creating datasets to train and refine AI systems—are frequently outsourced by commercial entities and academic institutions. Despite the vast and growing workforce of 435 million data workers enabling machine learning, their working conditions remain largely unaddressed, resulting in exploitative practices. Academic clients, in particular, lack clear guidance on how to outsource data work ethically and responsibly.
Great interest in the 13 high-density presentations
Together with Johannes Breuer, Silke Fürst, Erik Koenen, Dimitri Prandner, and Christian Schwarzenegger, Methods Lab member Christian Strippel organized a “Data, Archive & Tool Demos” session as part of the DGPuK 2024 conference at the University of Erfurt on March 14, 2024. The idea behind this session was to provide space to present and discuss datasets, archives, and software to an interested audience. The event met with great interest, so that all the seats were taken. After a high-density session in which all 13 projects were presented in short talks, the individual projects were discussed in more detail in the following poster and demo session in the hallway.
The 13 contributions were:
CKIT: Construction KIT — Lisa Dieckmann, Maria Effinger, Anne Klammt, Fabian Offert, & Daniel Röwenstrunk CKIT is a review journal for research tools and data services in the humanities, founded in 2022. The journal addresses the increasing use of digital tools and online databases across academic disciplines, highlighting the importance of understanding how these tools influence research design and outcomes. Despite their critical role, scholarly examination of these tools has been minimal. CKIT aims to fill this gap by providing a platform for reviews that appeal to both humanities scholars and technical experts, promoting interdisciplinary collaboration. For more details, see here.
Der Querdenken Telegram Datensatz 2020-2022 — Kilian Buehling, Heidi Schulze, & Maximilian Zehring The Querdenken Telegram Datensatz is a dataset that represents the German-speaking anti-COVID-19 measures protest mobilization from 2020 to 2022. It includes public messages from 390 channels and 611 groups associated with the Querdenken movement and the broader COVID-19 protest movement. Unlike other datasets, it is manually classified and processed to provide a longitudinal view of this specific movement and its networking.
DOCA – Database of Variables for Content Analysis — Franziska Oehmer-Pedrazzi, Sabrina H. Kessler, Edda Humprech, Katharina Sommer, & Laia Castro The DOCA database collects, systematizes, and evaluates operationalizations for standardized manual and automated content analysis in communication science. It helps researchers find suitable and established operationalizations and codebooks, making them freely accessible in line with Open Method and Open Access principles. This enhances the comparability of content analytical studies and emphasizes transparency in operationalizations and quality indicators. DOCA includes variables for various areas such as journalism, fictional content, strategic communication, and user-generated content. It is supported by an open-access handbook that consolidates current research. For more info, visit the project’s website here.
A “Community Data Trustee Model” for the Study of Far-Right Online Communication — Jan Rau, Nils Jungmann, Moritz Fürneisen, Gregor Wiedemann, Pascal Siegers, & Heidi Schulze The community data trustee model is introduced for researching sensitive areas like digital right-wing extremism. This model involves sharing lists of relevant actors and their online presences across various projects to reduce the labor-intensive data collection process. It proposes creating and maintaining these lists as a community effort, with users contributing updates back into a shared repository, facilitated by an online portal. The model aims to incentivize data sharing, ensure legal security and trust, and improve data quality through collaborative efforts.
Development and Publication of Individual Research Apps Using DIKI as an Example — Anke Stoll DIKI is a dictionary designed for the automated detection of incivility in German-language online discussions, accessible through a web application. Developed using the Streamlit framework, DIKI allows users to perform automated content analysis via a drag-and-drop interface without needing to install any software. This tool exemplifies how modern frameworks can transform complex analytical methods into user-friendly applications, enhancing the accessibility and reuse of research instruments. By providing an intuitive graphical user interface, DIKI makes advanced analytical capabilities available to those without programming expertise, thus broadening the scope and impact of computational communication science.
The FROG Tool for Gathering Telegram Data — Florian Primig & Fabian Fröschl The FROG tool is designed to gather data from Telegram, a platform increasingly important for social science research due to its popularity and resilience against deplatforming. FROG addresses the challenges of data loss and the tedious collection process by providing a user-friendly interface capable of scraping multiple channels simultaneously. It allows users to select specific timeframes or perform full channel collections, making it suitable for both qualitative and quantitative research. The tool aims to facilitate data collection for researchers with limited coding skills and invites the community to contribute to its ongoing development. An introduction to the tool can be found here.
Mastodon-Toolbox – Decentralized Data Collection in the Fediverse — Tim Schatto-Eckrodt The Mastodon Toolbox is a Python package designed for systematic analysis of user content and network structures on the decentralized social media platform Mastodon. Developed as an alternative to centralized platforms, Mastodon offers more privacy and control over data. The toolbox aids researchers in selecting relevant instances, filtering public posts by hashtags or keywords, collecting interactions such as replies, reblogs, and likes, and exporting data for further analysis. It is particularly useful for researchers with limited programming skills, enabling comprehensive data collection across Mastodon’s decentralized network. More info about the tool can be found here.
Open Source Transformer Models: A Simple Tool for Automated Content Analysis for (German-Speaking) Communication Science — Felix Dietrich, Daniel Possler, Anica Lammers, & Jule Scheper The “Open Source Transformer Models” tool is designed for automated content analysis in German-language communication science. Leveraging advancements in natural language processing, it utilizes large transformer-based language models to interpret word meanings in context and adapt to specific applications like sentiment analysis and emotion classification. Hosted on the Open Source platform “Hugging Face,” the tool allows researchers to analyze diverse text types with minimal programming skills.
Meteor: A Research Platform for Political Text Data — Paul Balluff, Michele Scotto di Vettimo, Marvin Stecker, Susan Banducci, & Hajo G. Boomgaarden Meteor is a comprehensive research platform designed to enhance the study of political texts by providing a wide range of resources, including datasets, tools, and scientific publications. It features a curated classification system and an interlinked graph structure to facilitate easy navigation and discoverability of resources. Users can contribute new resources, create personalized collections, and receive updates through a notification system. Additionally, Meteor integrates with AmCAT 4.0 to enable non-consumptive research, ensuring the protection of copyrighted materials. For more details, visit the project’s website here.
rufus – The Portal for Radio Search — Patricia F. Blume The “rufus” tool is an online research platform developed by the Leipzig University Library (UBL) to provide easy access to broadcast information from the ZDF archive. This platform allows researchers to search production archive data from an external source for the first time, offering data from nearly 500,000 broadcasts and 2 million segments dating back to 1963. The tool features a versatile user interface with specific search instruments, enabling straightforward viewing requests to the ZDF archive. Built with open-source components, rufus not only facilitates access to valuable audiovisual heritage for communication and media researchers but also supports the integration of additional data providers. For more details, visit the project’s website here.
Weizenbaum Panel — Martin Emmer, Katharina Heger, Sofie Jokerst, Roland Toth, & Christian Strippel The Weizenbaum Panel is an annual, representative telephone survey conducted by the Weizenbaum Institute for the Networked Society and the Institute for Journalism and Communication Studies at the Free University of Berlin. Since 2019, around 2,000 German-speaking individuals over the age of 16 are surveyed each year about their media usage, democratic attitudes, civic norms, and social and political engagement, with a special focus on online civic interventions. The survey allows for longitudinal intra-individual analyses and the data is made available for scientific reuse shortly after collection. More information about the panel can be found here.
WhatsR – An R Package for Processing and Analyzing WhatsApp Chat Logs — Julian Kohne The WhatsR R-package enables researchers to process and analyze WhatsApp chat logs, addressing the gap in studying private interpersonal communication. It supports parsing, preprocessing, and anonymizing chat data from exported logs, while allowing researchers to analyze either their own data or data voluntarily donated by participants. The package includes a function to exclude data from non-consenting participants and is complemented by the ChatDashboard, an interactive R shiny app for transparent data donation and participant feedback. The package can be found here.
OpenQDA — Andreas Hepp & Florian Hohmann The OpenQDA tool is an open source qualitative data analysis tool, and the latest product developed at the ZeMKI institute in Bremen. It is provided as free-to-use research software that enables collaborative text analysis and all basic functions of other QDA software. The tool that is currently still in its beta version can be found here.
On April 10th and 11th, The Methods Lab organized the second edition of the workshop Introduction to Programming and Data Analysis with R. Led by Roland Toth from the Methods Lab, the workshop was designed to equip participants with fundamental R programming skills essential for data wrangling and analysis.
Roland Toth introduces participants to data wrangling with R
Across two days, attendees engaged in a comprehensive exploration of R fundamentals, covering topics such as RStudio, Markdown, data wrangling, and practical data analysis. Day one focused on laying the groundwork, covering the main concepts in programming including functions, classes, objects, and vectors. Participants were also familiarized with Markdown and Quarto, enabling them to include analysis results while producing text, and the key steps and techniques of data wrangling.
Participants work on their own research questions during the practical exercise
The first half of the second day was dedicated to showcasing and exploring basic data analysis and various visualization methods. Afterwards, participants had the opportunity to put into practice the knowledge they had gained from the previous day by working with a dataset to formulate and address their own research questions. Roland was on hand to offer assistance and guidance to the participants, addressing any challenges or concerns that arose along the journey.
Christian Strippel presents first results
The workshop fostered a collaborative learning environment, with lively discussions and ample questions from all. We thank all participants for their active involvement!
The use of online surveys in contemporary social science research has grown rapidly due to their many benefits such as cost-effectiveness and ability to yield insights into attitudes, experiences, and perceptions. Unlike more established methods such as pen-and-paper surveys, they enable complex setups like experimental designs and seamless integration of digital media content. But despite their user-friendliness, even seasoned researchers still face numerous challenges in creating online surveys. To showcase the versatility and common pitfalls of online surveying, Martin Emmer, Christian Strippel, and Roland Toth of the Methods Lab arranged the workshopIntroduction to Online Surveyson February 22, 2024.
Martin gave a presentation on the design and logic of online surveys.
In the first segment, Martin Emmer provided a theoretical overview of the design and logic of online surveys. He started by outlining the common challenges and benefits associated with interviewing, with a particular emphasis on social-psychological dynamics. Compared to online surveys, face-to-face interviews offer a more personal, engaging, and interactive experience, enabling interviewers to adjust questions and seek clarification of answers in real time. However, they can be time-consuming and expensive and may introduce biases such as the interviewer effect. On the other hand, the process of conducting online surveys presents its own set of challenges, such as limited control over the interview environment, a low drop-out threshold, and particularities connected with self-administration such as the need for detailed text-based instructions for respondents. Nevertheless, self-administered and computer-administered surveys boast numerous advantages, including cost-effectiveness, rapid data collection, the easy application of visuals and other stimuli, and accessibility to large and geographically dispersed populations. When designing an online survey, Martin stressed the importance of clear question wording, ethical considerations, and robust procedures to ensure voluntary participation and data protection.
Christian shared his insights on survey creation using online access panel providers.
In the second part of the workshop, Christian Strippel delved into the realm of online access panel providers, including the perks and pitfalls associated with utilizing them in survey creation. Panel providers serve as curated pools of potential survey participants managed by institutions, such as Bilendi/Respondi, YouGov, Cint, Civey, and the GESIS Panel. Panel providers oversee the recruitment and management processes, ensuring participants are matched with surveys relevant to their demographics and interests, while also handling survey distribution and data collection. While the use of online panels offers advantages such as accessing a broad participant pool, cost-efficiency, and streamlined sampling of specific sub-groups, they also have their limitations. Online panels are, for example, not entirely representative of the general population as they exclude non-internet users. Moreover, challenges arise from professional respondents such as so-called speeders who rush through surveys, and straight-liners who consistently choose the same response in matrix questions. Strategies to combat these issues include attention checks throughout the questionnaire, systematic exclusion of speeders and straight-liners, and quota-based screening. To conclude, Christian outlined what constitutes a good online panel provider, and shared valuable insights into how to plan a survey using one effectively.
Participants learned how to create their own survey using LimeSurvey during Roland’s live demo.
The third and final segment of the workshop featured a live demonstration by Roland Toth on how to set up an online survey using the open-source software LimeSurvey, which is hosted on the institute’s own servers. During this live demonstration, he created the very evaluation questionnaire administered to the workshop participants at the end of the workshop. Roland began by providing an overview of the general setup and relevant settings for survey creation. Subsequently, he demonstrated various methods of crafting questions with different scales, display conditions, and the incorporation of visual elements such as images. Throughout the demo, Roland addressed issues raised earlier in the first part of the workshop concerning language and phrasing, emphasizing rules for question-wording and why it is important to ask for one piece of information only per question. The live demonstration was wrapped up with a segment on viewing and exporting collected data. After letting the participants complete the evaluation form, the workshop concluded with a Q&A session.
During my visit to the Center for Industry 4.0, I had the opportunity to participate in the pretest of the HoloLens study and learn more about augmented reality-based learning. The goal of the study, which is a collaboration between the research groups ofGergana Vladova(Education for the Digital World) and Martin Krzywdzinski (Working with Artificial Intelligence), is twofold. In the first part, the research groups investigate the effectiveness of different Augmented Reality (AR) designs on learning and compare them to traditional paper-based methods by using eye-tracking. In the second part, they focus on participants’ decision making and disruption management, guided by suggestions from an AI-assisted system. These participants can operate in either a team-based or hierarchical setting.
The cube travels along the conveyor belt, its screen showcasing lenses for participants to identify and sort out. The AR glasses used in the HoloLens study.
In the first part of the experiment, participants work in a simulated factory environment where they are tasked with producing lenses. The team uses either AR instructions or traditional paper instructions, depending on the experimental condition. The AR head-mounted display guides the team through tasks such as adjusting machine settings, sorting defective lenses, and other simulated problems. The same principle is used in the other experiments, except in this case, participants rely on paper-based learning instead of AR glasses.
In the second part of the experiment, participants apply what they learned in the first part, but without using the AR glasses or the paper instructions. In addition, the errors they must solve are different from those in the previous part. When presented with a problem, participants are expected to solve it collaboratively through effective communication and with the help of AI.
To measure performance, the study uses traditional metrics such as time and error rates. Between each round, knowledge tests in the form of a questionnaire are administered to assess participants’ recall and comprehension. The hypothesis is that process-integrated learning via Augmented Reality can enhance the learning process.
Nicolas Leins and Jana Gonnerman at the Centre for Industry 4.0 Potsdam.
The Weizenbaum Institute conducts research in a variety of ways. To provide an insight into the different research practices, from now on the Methods Lab will be presenting selected projects in longer features. For the first text in this series, Anna Hohwü-Christensen visited the Berlin Open Lab (BOL) to meet Ines Weigand and Corinna Canali from the research group Design, Diversity and New Commons.
I first met Ines and Corinna at the BOL in June, where they led the workshop Flushed Away: A Workshop on Disgust, Gender, and the Technical Object as part of the DGTF’s (Deutsche Gesellschaft für Design-Theorie und -Forschung) Design and Digital Justice Conference. Ines and Corinna are research associates affiliated with the Weizenbaum Institute through the research group Design, Diversity and New Commons. A group that, in turn, forms a cornerstone in the Design Research Lab initiative—a network of researchers and organizations that aim to bridge the gap between technological innovations and people’s real needs.
BOL is a dynamic and experimental space that brings together experts from design, engineering, the humanities, and maker communities. Based at the University of Arts Berlin (UdK) in Berlin-Charlottenburg, it acts as a convergence point for four institutions: Weizenbaum Institute, UdK, Technical University, and the Einstein Center Digital Future. Home to numerous transdisciplinary research projects, events, and conferences, BOL operates with the mission of application-oriented and inclusive design of human-technology interaction, and transparent, participatory research.
Following my initial visit, I decided to find out more about the lab and the part played by the Weizenbaum Institute within its intricate framework. During a comprehensive tour, I got to chat with Ines and Corinna not only about the space and its many diverse projects, but also about research and interdisciplinarity in design practices, and the importance of critical thinking in material making.
A map of the various spaces at BOL.
Anna: Can you tell me a bit about the Berlin Open Lab? What is it and how does it function?
Ines: BOL is an experimental space for transdisciplinary research projects at the intersection of technology, society, and arts. It has its own laboratory for digital-based production, smart material interfaces, and wearable computing plus a space for design research with augmented and virtual realities. There is this idea of shared resources and experiences, and flexible and agile working which they try to support with the spatial design of the space. Everything is movable and adaptable here, every group has their space to work in, but it is kind of fluent and changing. So when a new project comes in, you see how you can support them in their working structure, combining it with the spatial aspect. Behind this glass wall is the machine tool area.
And this is the working and event space. I can show you what kind of projects are in here as far as I know, but sometimes it also happens to me that, for example, when the BOL symposium was here, and there were so many projects presented… It’s like oh, I never knew that you are here, but officially, they also have this space.
[laughter]
Anna: I sometimes feel like that at the Weizenbaum Institute. There is just so much going on. Is the lab generally open to students who want to use this space?
Ines: There was, for example, this project by a student who was working on her master’s thesis. The project was about breast cancer patients who are losing one or two breasts. Apparently, there are only three shapes or so that you can go for if you are getting an artificial breast, so she tried to develop a process where you can scan the breast and get a prosthesis that is closer to the original shape. She applied for it, and was then able to use the space.
Anna: How many people work here on average on a full day?
Ines: It’s very different. There are maybe fifteen people here on a full day because not everyone is in here all the time. If people need to write, they are not here because it can get too noisy. It is more if they want to use the machines, tools, meet, and work on something together. And if you have silent work, like writing or something…
Corinna: That is why I am not sitting here.
[laughter]
Corinna: Never here…
Workspaces from the Design, Diversity and New Commons group.Various student projects on display.
Ines: This is the space from our research group Design Diversity, and New Commons. I am mainly sitting here with Michelle Christensen and Florian Conradi, and our two working students. We use experimental research methods that come out of design, so we are using mainly critical making as a method. This is an approach where you try to combine critical thinking or critical theory—which comes from the humanities—with material production. So the courses we give are always called something like Politics of Machines or Design and Conflict, but they all follow the same structure where students get to know a field of, let’s say, critical theory. It is mainly about technology, but our last course was on the relationship between the environment and humans. The students get a specific perspective with which they look at design and try to use design as a form of critical medium, a tool to bridge this way of critical thinking with material making. The objects that you see hereare from different courses that the students had. They build objects or artifacts that are not meant to work in a way so that you can scale them up and bring them to market, but that is more about exploring a way of thinking in materiality. So it is kind of like a critical thought translated into materiality. They are more like curious objects.
Ines and a student project on surveillance capitalism.Print-outs of data collected through cookies of user activity on different websites.
Ines: This was made by a student who looked into surveillance capitalism. He looked into cookies and how much data is constantly saved from you when you are surfing on the internet. As a project, he made this little printer box, where the data of the cookies that the website saved from you is printed in real-time. This, for example, is just 30 seconds of Yahoo!
Anna: Oh, wow.
Ines: And here you can see the different websites and how much data they are saving from you.
Anna: It is interesting to have it printed out like that.
Ines: Yeah. It is interesting because then you can actually see what cookies are. Because if you have a look at it, at some point, you are on a completely different website. And then Spotify turns up and it is like what, this is not the website I am on, but they are checking out everything you do on your computer, what programs you have open. And then you get it. What cookies actually are and what information they are getting from you.
Ines: And this is a project from Pablo. He wanted to find out about how we can get another approach or feeling about what is going on around us in the environment. He installed a CO2 sensor in a box and programmed it in a way so that it gives you a noise signal about how much CO2 is in the air. So you have another approach to what pollution is or how much pollution, or in this case, CO2, is in the air around us.
Anna: So it creates a sound depending on how much CO2 there is?
Ines: Exactly. The more CO2 there is, the more sound there is.
Anna: That is fascinating. And very creative!
Ines: Yeah. And this is a project where a student was looking into the weird fact that in some parts of the world, it is easier to get Coca-Cola than clean water. The sad story behind it is that clean water is somehow used to produce this Coca-Cola. So she made this as a critical object, a filter that turns Coca-Cola into water, filtering out mainly the sugar and other things, to highlight this weird fact. And that is the sense behind it. To highlight an issue, set up a specific critique, or come up with an alternative way of thinking. While the students are doing prototyping, they learn about technology and the power relations embedded in them, how they function, and how to use them and work with them by building up their own critiques and combining it with practical making. They have to deal with sensors and technology. That is the way they learn to approach this field—by really doing something combined with critical thinking.
Corinna: My part of the research group—that is now just Bianca Herlo and I—we don’t work here and we are not working specifically on design as a tool to make something. We are using design, artistic research, and visual culture research to analyze bias within the digital realm and technology to unpack issues that are mostly unseen. Because like with cookies, they are running in the background, and you need to have tools to visualize them to figure out how they function, how many they are, and how invasive they can be. And this is pretty much the Design Research Lab and what everyone is doing. So this [ground floor] is one part, but then there is the expanded part that mostly sits on the second floor. There are people working in artificial intelligence, in theory per se, in policy-making. It is a broad organism, the Design Research Lab.
Ines: And the BOL is more the practical side of it, a space that was introduced to allow people from a lot of different institutions to use shared tools, machines, knowledge, and open-source libraries. It is not an organization, it is a platform. For us, the main thing is to do research about design methods, and what they can contribute to lacks or errors in current research. Design research methods are often about trying to bridge between different concepts. That is the idea behind it.
A mannequin head wrapped in plastic.A student project on space farming.
Corinna: The research group is made up of the three of us [refers to student worker Selenay], Athena, and the heads. What we are doing sounds very different from when you actually see the projects that we are working on. Ines and I are both doing our PhDs. I am mostly working on gender bias within internet governance, and Ines is working on practical…
Ines: Practical bridging of the gap between humans and the environment.
Corinna: From the perspective of…
Ines: …the post-humanities.
Corinna: In a way, we found out that we are working on something that has a connection when we did a workshop.
Anna: I was there, yeah, I remember it.
Corinna: The workshop made us realize that there is a common ground. That is, I am working mostly on content moderation, so what gets excluded from the internet and what is allowed. Ines is working on bodily waste and the creation of waste, what the meaning and political significance is of making something into waste and having to throw it out. We are approaching subjects from very different perspectives. I come from visual culture, design, and art, and I am employing analytical methods to analyze image production and consumption online. It is two different ways of experimenting with different kinds of technologies. One is to do more with chemical and biochemical technology. Mine is more digital.
Corinna: Yes, and also moving across disciplines, which is why design research and artistic research have started to grow in the past few years… Because actually they can move across disciplines.
Ines: …and other disciplines struggle with that.
Corinna: Yes, other disciplines are very much constrained within their own boundaries. It is difficult to find people working on artificial intelligence that moves outside of data or computer science. When you are working within design research, it is kind of natural and organic that you grasp from all the disciplines that belong to that, also in some peripheral ways, not just directly. This is kind of what everyone is doing in this space, in a way. It gives you the tools to move across whatever.
Ines: We are using a process called research through design, so we are actively using the design process itself as an epistemological source. We are designing, and while we are designing we are reflecting on the design process and getting specific knowledge out of it. It is a very practical way of doing research.
Anna: Do you know if there are other labs that have this approach?
Ines: I think there is a whole movement that is trying to implement open labs. I don’t know if they are also doing research. I think that is the special thing here. It is an open, shared lab, but it is also an open shared lab where you are doing research on what is happening. Coming out of the maker movement, there are a lot of areas where people are trying to develop open labs, where you can share machines and access technology like laser cutting and 3D printing.
Corinna: There are similar things, but they are mostly focused and financed by industries. So the end goal is not to produce research, but to produce a commodity or something that can be turned into products. The main focus here is research and not producing something that becomes a mass product ready for market. It is to apply a critical, analytical approach to what you are putting out in the world.
Ines: Yeah, there are a lot of labs but not combined with a research focus. We are doing practical making, but also research on practical making through practical making. It is about what value the practical work has in research. There’s a lot of theory also, and for a long time, the material part was missing. Then the material turn came with the idea that we cannot be completely separated from the material world around us… And now they’re trying to find concepts of how to combine those again.
Corinna: At the beginning, it was mostly circumscribed to industrial and product design, and then it kind of started filtering through and moving within the design spectrum as a whole.
Ines: Yeah. And it is still a very young field. I think the whole design research field is still finding itself. It is not like there is one way and everyone is on the same page. There are a lot of different things going on now, people are trying things and having open discussions. It is still an experimental ground.
Research associates Corinna Canali and Ines Weigand.
The amalgamation of previously two separate groups, Design, Diversity, and New Commons is part of the Design Research Lab initiative based at the BOL at UdK Berlin. Led by principal investigator Gesche Joost, the group is comprised of research heads Michelle Christensen, Florian Conradi, and Bianca Herlo, research associates Ines Weigand and Corinna Canali, and student assistants Athena Grandis and Selenay Kiray.
On June 15, the Methods Lab organized the workshop Introduction to Topic Modeling in collaboration with the research groupPlatform Algorithms and Digital Propaganda. The workshop aimed to provide participants with a comprehensive understanding of topic modeling – a machine-learning technique used to determine clusters of similar words (i.e., topics) within bodies of text. The event took place at the Weizenbaum Institute in a hybrid format, bringing together researchers from various institutions.
The workshop was conducted by Daniel Matter (TU Munich) who guided the participants through basic concepts and applications of this method. Through theory, demonstrations, and practical examples, participants gained insight into commonly used algorithms such as Latent Dirichlet Allocation (LDA) and BERT-based topic models. The workshop enabled participants to assess the advantages and drawbacks of each approach, equipping them with a foundation in topic modeling while, at the same time, providing plenty of new insights to those with prior expertise.
Daniel Matter talks about the most important aspects of topic modeling.
During the workshop, Daniel explained the distinction between LDA and BERTopic, two popular topic modeling strategies. LDA, or Latent Dirichlet Allocation, a commonly used method for topic modeling, operates as a generative model and treats each document as a mixture of topics. LDA aims to determine the topic and word distributions that maximize the probability of generating the documents in the corpus. With LDA, as opposed to BERTopic, the number of topics must be known beforehand.
BERTopic, on the other hand, belongs to the category of Embeddings-Based Topic Models (EBTM), which take a different approach. Unlike LDA, which treats words as distinct features, BERTopic incorporates semantic relationships between words. BERTopic follows a bottom-up approach, embedding documents in a semantic space and extracting topics from this transformed representation. Unlike LDA, which can be applied to short and long text corpora, BERTopic generally works better on shorter text, such as social media posts or news headlines.
The workshop took place in the Flex Room at the Weizenbaum Institute.
When deciding between BERTopic and LDA, it is essential to consider the specific requirements of the text analysis. BERTopic’s strength lies in its flexibility and ability to handle short texts effectively, while LDA is preferred when strong interpretability is needed.
Participants were able to engage with the method on their own devices during the presentation.
With this workshop, we at the Methods Lab hope to have provided our attendees with a solid understanding of topic modeling as a method. By exploring the concepts, applications, and advantages of each approach, these tools can be used to unlock hidden semantic structures within textual data, enabling researchers to employ them in various domains and facilitating tasks such as document clustering, information retrieval, and recommender systems.
A big thank you to Daniel for inducting us into the world of topic modeling and to all our participants!
Our next workshop, Whose Data is it Anyway? Ethical, Practical, and Methodological Challenges of Data Donation in Messenger Groups Research, will take place on August 30, 2023. See you there!
Data is an invaluable asset for scientific research. However, accessing platform data for academic purposes has become increasingly challenging, particularly with the closure of free access to APIs like Twitter’s. Recognizing the significance of data accessibility for research, the Weizenbaum Institute organized the workshop Datenzugang für die Forschung – Der Digital Services Act (DSA)in collaboration with the European New School of Digital Studies (ENS) to explore the potential of the upcoming Digital Services Act (DSA) in facilitating data access for academic research.
The DSA is set to bring about improvements in data access for researchers under Article 40. However, the DSA’s regulations must be thoughtfully implemented at the national level to achieve these goals fully. With the closure of free access to Twitter’s API, there is an urgency to find robust solutions to enable researchers to access platform data for scientific inquiry. The DSA, expected to come into force in February 2024, holds promises to provide avenues for researchers to obtain the data they need for their academic research. Still, it also brings about its own set of challenges.
The workshop aimed to foster an open forum where researchers from diverse disciplines, particularly those who work or plan to work with platform data, could come together to provide recommendations for the effective implementation of the DSA. Organized by Ulrike Klinger (ENS) and Jakob Ohme (WI) and supported by the Stiftung Mercator, the workshop addressed crucial questions surrounding data access requests, eligible data, and the verification process by authorities and platforms.
The workshop started with a welcoming address from Ulrike Klinger. Jakob Ohme then provided an overview of the DSA’s Article 40, shedding light on its potential implications for researchers. This was followed by presentations on the DSA’s implementation in Germany by Gökhan Cetintas from the Bundesministerium für Digitales und Verkehr and Andrea Sanders-Winter from the Bundesnetzagentur, who offered insights into the data access rules under the DSA.
After a coffee break, Jessica Gabriele Walter from Aarhus University presented on DSA40 and scholarly networks in other EU countries, providing a broader perspective on data access challenges and solutions. Richard Kuchta from Democracy Reporting International later delved into “The Data Access Problem” and emphasized the necessity of a vetting process to ensure data security and accuracy.
The latter part of the workshop involved group work in which participants engaged in the discussion and expansion of a policy paper draft prepared by the Weizenbaum Institute and ENS, based on inputs from an early expert round. The goal was to develop actionable recommendations that would benefit the research community in Germany and the EU. Breakout sessions centered on topics like “Vetting Access,” “Access Modes,” and “Infrastructure,” allowing participants to delve deeper into specific aspects of data access.
The workshop brought together an interdisciplinary group of researchers with a shared vision: enabling access to platform data for academic purposes. By combining their expertise and perspectives, participants crafted recommendations for the effective implementation of the DSA, ensuring that data access for research remains equitable and secure. As the DSA comes into force and takes shape, the outcomes of this workshop are expected to serve as a significant step forward in fostering inclusive dialogue on the future of data accessibility.
Researchers in the EU are about to have a new legislative framework to access and study data held by platforms and search engines in the form of Article 40 of the Digital Services Act (DSA) – a major milestone in platform regulation history expected to have spillover effects worldwide. As part of the Thursday Lunch Talk Series, Jakob Ohme (WI) and the Methods Lab jointly organized a talk to gain more insight into what Article 40 means in the context of German law, and the consequences it might have on researchers’ access to platform data. Tupperware and brown paper bags in hand, hungry participants gathered in the Flexraum to listen to Jakob give the ABCs of the EU’s new data access regime and discuss some of its opportunities, limitations, and grey areas.
Here is a quick summary of Article 40:
Providers of very large online platforms (VLOPs) or search engines (VLOSEs) shall provide access to data necessary for monitoring and assessing compliance with the DSA, at their reasoned request and within a reasonable period specified in that request, access to data necessary to monitor and assess compliance with this regulation.
Data accessed can only be used for monitoring and assessing compliance while taking into account the rights and interests of the platform providers, service recipients, personal data protection, and the security of their services.
Platforms must explain the design, logic, functioning, and testing of their algorithmic systems, including recommender systems, upon request.
Vetted researchers can request access to data to conduct research on “systemic risks” in the EU and assess risk mitigation measures.
Within 15 days, platforms can request to amend a data access request as referred to in §4 if: (a) they do not have access to the data (b) giving access to the data will lead to significant vulnerabilities in the security of their service or the protection of confidential information, particularly trade secrets.
Requests for amendment pursuant to §5 should propose alternative means for providing access to appropriate and sufficient data.
Platform providers or search engines shall facilitate and provide access to data pursuant to §1 and §4 through appropriate interfaces specified in the request, including online databases or application programming interfaces.
Researchers can be granted the status of “vetted researchers” if they meet specific conditions, including affiliation with a research organization, independence from commercial interests, disclosure of research funding, capability to fulfill data security requirements, and commitment to making research results publicly available.
Researchers can submit applications to the DSC of the Member State they are affiliated with, who conducts an initial assessment before forwarding the application to the DSC of Establishment for a final decision.
The DSC can terminate data access for vetted researchers if they no longer meet the conditions. The coordinator must inform the platform provider and allow the researcher to respond before terminating access.
DSCs must inform the Board about vetted researchers and their research purposes. If access to data is terminated, they must also inform the Board.
Platforms must provide timely access to publicly accessible data, including real-time data, to researchers who meet the conditions and use it for research on systemic risks.
With input from the Board, the Commission will adopt delegated acts to specify technical conditions for data sharing, including with researchers, while considering the rights and interests of platforms and service recipients, protection of confidential information, and maintaining service security.
Both presenter and the audience highlighted several aspects regarding the infrastructure and implications of the article, which made for a vibrant, fruitful discussion. One question focused on the effort platforms would need to make in order to prevent researchers from acquiring data (§5). Though making a projections at this point in time is challenging due to the remaining unknowns, lawyers predict that platforms will try to prevent researchers’ access to data more for certain areas than others. One such area could be questions pertaining to algorithms, which would fall under the so-called “trade-secret exemption.” Another topic of discussion was the “systemic risk research” requirement (§4). More specifically, what do we mean when we speak of systemic risks? As a term that can be understood very widely, it would be possible, hypothetically speaking, to file a request as long as one can argue for a broader understanding of it.
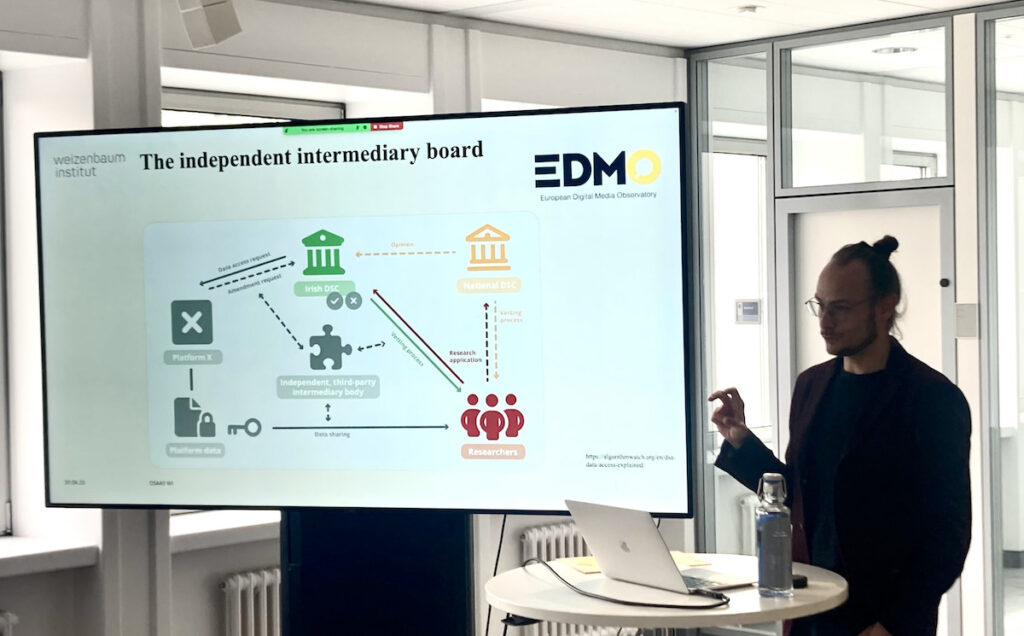
Some details regarding the data vetting process and its implementation remain unclear, such as the establishment of an independent advisory mechanism and the technical conditions under which it would operate. Most of the largest platforms and search engines are based in Ireland, so the DSC of Establishment tasked with vetting researchers will likely be the Irish DSC in many cases. Researchers can also send their applications to their country’s national digital services coordinator. In terms of regulatory oversight in Germany, it is anticipated that the Bundesnetzagentur will play a significant role as the DSC regulator. The future German DSC will be able to provide an opinion about whether to grant a data access request, but the final decision will remain in the hands of the Irish DSC.
DSCs are yet to be appointed by EU member states, and complex vetting may require an independent advisory body responsible for this task. However, the establishment of an independent advisory mechanism comes with its own set of challenges. How much power will the board have? And how will the board make its decisions? During the talk, the difficulty of dealing with and assessing raw data when one does not know what to look for was identified as another potential issue. An alternative model could involve access to publicly accessible data without vetting. This approach would be similar to what the Twitter API has provided in the past, and it may prove to be an exciting option for fueling research, primarily if implemented in real-time and through application programming interfaces.
This edition of the Thursday Lunch Talk Series shed light on several key aspects of Article 40, emphasizing the opportunities and challenges it could create for researchers’ access to platform data in the future. While some details, such as the data vetting process, remain uncertain, the presentation sparked valuable discussions, highlighting the complexities and considerations involved in what lies ahead for platform providers, researchers, and lawmakers in navigating our digital landscape.
On March 2nd, the Methods Lab hosted its first-ever workshop, Web Scraping and API-based Data Collection. The workshop explored various techniques for accessing and gathering data from platforms using APIs and web scraping. Speakers included Florian Primig (FU Berlin), Steffen Lepa (TU Berlin), Felix Gaisbauer (WI), and Leon Wendel (WI). The workshop received an overwhelmingly positive response, with many people attending both in person and remotely. It generated plenty of discussions and concluded with a Q&A session.
Lion Wedel gives an introduction to Web-Scraping (photo: Roland Toth).
Thanks to all our presenters and participants in helping us create such a successful first event. We look forward to organizing more workshops in the future on emerging methodologies in the realm of digital research!
Manage Cookie Consent
To provide the best experiences, we use cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.