On April 28, 2026, researchers from the WI gathered for an engaging workshop introducing Open Paper – a next-generation content management system designed to break free from the constraints of traditional publishing formats. The session centered on a core idea: knowledge shouldn’t be confined to linear, static documents. Instead, Open Paper enables dynamic, interactive publications that adapt to how readers actually engage with content. By replacing rigid PDFs and blog posts with modular, navigable experiences, the platform empowers authors to create richer, more intuitive reading experiences. The workshop was organized by Merja Mahrt and Esther Görnemann from WI together with the Methods Lab, and Markus Brandenburg and Fabian Hassel from the agency that has developed Open Paper – MADEFUL – were invited as speakers.
In the workshop, participants explored how Open Paper transforms static text into living publications. Through a hands-on demo, they discovered features like:
- Modular content blocks (text, multimedia, citations, sticky notes, animations)
- Flexible layouts with multi-column arrangements and responsive design
- Interactive expositions that allow readers to dive deeper into subtopics while maintaining context
- Self-contained chapters that make content accessible even when read out of order

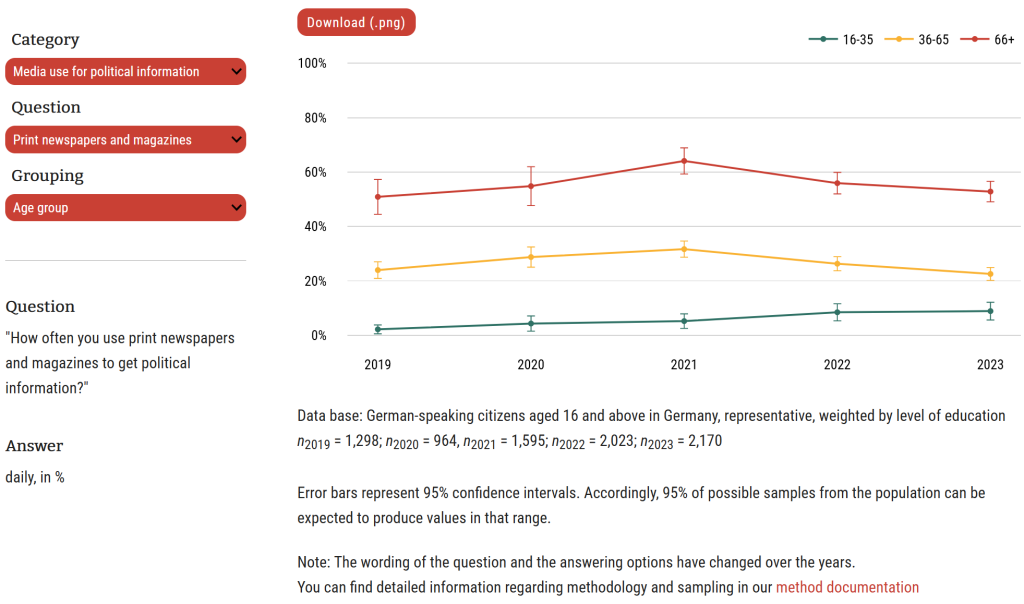
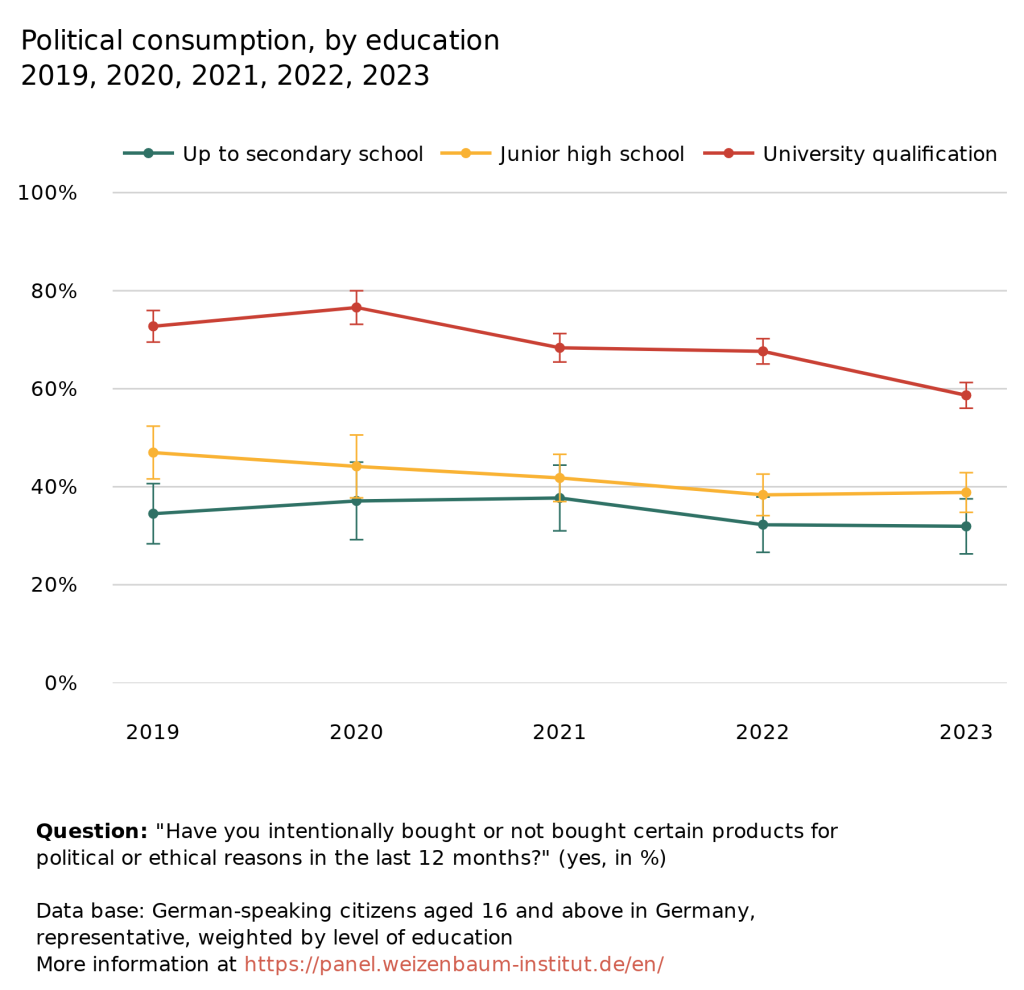
The real impact was seen in an overview over digital sovereignty as part of the Weizenbaum fundamental series – a flagship example of what’s possible. With interactive visuals, side-by-side comparisons, and layered explanations, the publication achieved an average reader engagement of 26 minutes, which is a clear indicator of depth and interest. Even more telling: traffic increasingly comes from AI tools like ChatGPT, signaling that the content is not only readable but reusable and referable in emerging digital workflows.
Beyond design, Open Paper was built on strong ethical and technical foundations: open source, open access, GDPR-compliant, CO₂-neutral hosting, SEO-friendly, and fully accessible. Like the Weizenbaum Institute, other institutions can also deploy a custom instance aligned with their corporate design, ensuring brand consistency and long-term ownership.
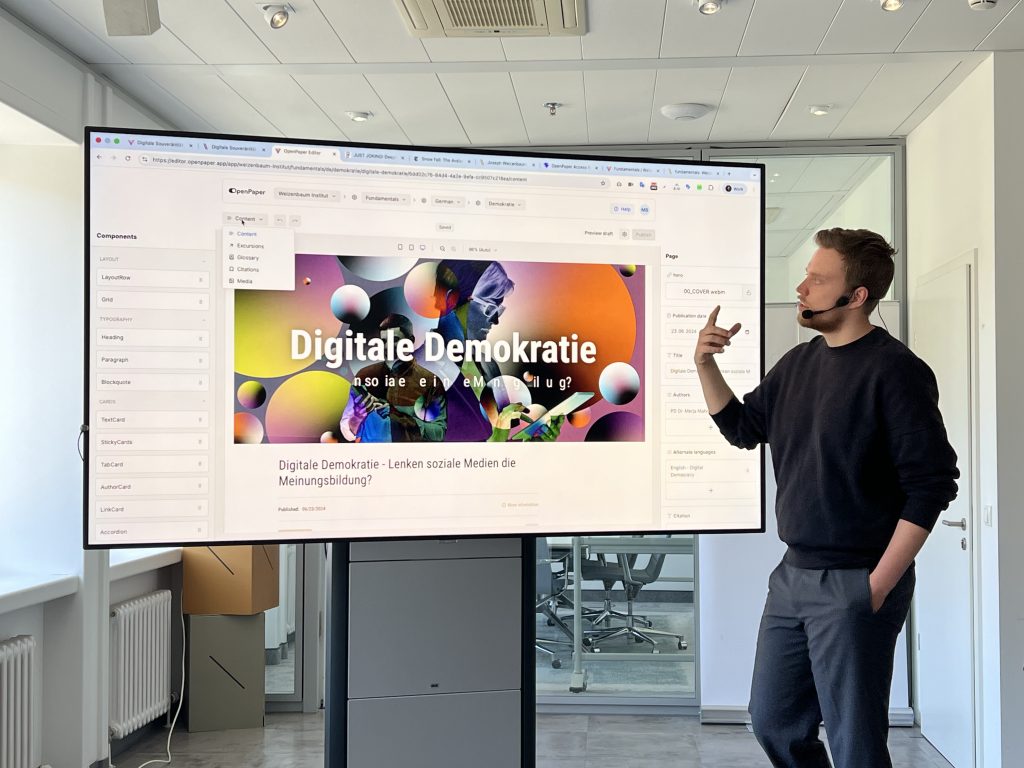
The workshop’s interactive phase let participants discover how to build a page in real time using a three-panel interface:
- Left: Structure and layout tools (grid, headings, visual elements)
- Center: Live preview of content and layout
- Right: Contextual editing options for the selected element
Beyond the workshop itself, the presenters further created a tutorial video made available on the WI’s Open Paper instance.
Rather than offering a one-size-fits-all template, Open Paper encourages authors to think critically about audience, structure, and engagement. It represents a shift in how we think about knowledge sharing: interactive, inclusive, and built for the future.